Developer Tutorials
AI B-roll Generator API: Automate with JSON
Automate B-roll with JSON using Zvid. Turn AI or editorial cues into timed media layers, templates, and API-rendered videos.
Published May 16, 2026

AI B-roll Generator API: Automate with JSON
To automate B-roll with JSON, represent each supporting clip, image, or graphic as a timed visual layer with a source URL, start time, end time, position, size, resize mode, and track order. In Zvid, those B-roll assets live in the same visuals array as titles, captions, overlays, and other scene elements, so your application can generate B-roll placement from scripts, product feeds, transcript cues, or editorial rules instead of editing every video by hand.
The core API flow is: build the JSON payload, submit it to POST https://api.zvid.io/api/render/api-key, then poll GET https://api.zvid.io/api/jobs/{id} until the render completes. Keep the JSON Structure overview, Image Elements reference, Video Elements reference, and Transitions reference nearby while you implement.

B-roll automation works best when editorial intent becomes structured timing data.
If you are new to Zvid's render model, start with How to Generate a Video from JSON, then compare this B-roll workflow with the broader JSON to Video API guide and the product-data pattern in How to Create Product Videos from a CSV or Product Feed.
Here is the public API loop most implementations need:
curl -X POST https://api.zvid.io/api/render/api-key \
-H "Content-Type: application/json" \
-H "x-api-key: YOUR_API_KEY" \
-d @broll-render.json
curl -X GET https://api.zvid.io/api/jobs/$JOB_ID \
-H "x-api-key: YOUR_API_KEY"
The JSON model for automated B-roll
B-roll automation is a timeline problem. Your app needs to know which media asset should appear, when it should appear, how it should fit the frame, and whether it should sit behind or above the primary story layer.
In Zvid, each B-roll item can be modeled as a visual element:
IMAGEfor product photos, screenshots, still frames, thumbnails, or generated graphics.VIDEOfor short supporting clips, demonstrations, background footage, or reaction shots.GIFfor lightweight animated accents.SVGorTEXTfor generated labels, callouts, diagrams, or timeline overlays.
The fields that matter most for B-roll are src, enterBegin, enterEnd, exitBegin, exitEnd, width, height, position, anchor, resize, track, opacity, and the optional animation or transition fields. The Submit render job reference documents the hosted render endpoint, and the Get render job status reference documents job polling after submission.
For example, a production B-roll image layer can look like this:
{
"type": "IMAGE",
"src": "https://cdn.pixabay.com/photo/2024/10/02/18/24/leaf-9091894_1280.jpg",
"width": 1280,
"height": 720,
"position": "center-center",
"resize": "cover",
"enterBegin": 2.2,
"enterEnd": 2.6,
"exitBegin": 5.8,
"exitEnd": 6.2,
"track": 2,
"enterAnimation": "fade",
"exitAnimation": "fade"
}
For a short supporting clip, use VIDEO with the same timeline fields and add source trimming when needed:
{
"type": "VIDEO",
"src": "https://cdn.pixabay.com/video/2025/06/03/283533_large.mp4",
"width": 1280,
"height": 720,
"position": "center-center",
"resize": "cover",
"videoBegin": 4,
"videoEnd": 9,
"enterBegin": 6,
"exitEnd": 11,
"volume": 0,
"track": 2
}
Use volume: 0 when B-roll should not override narration, voiceover, or background music. If the B-roll clip should contribute audio, keep the volume intentional and test it against the rest of the mix.
Copy-paste Zvid B-roll timing payload
The renderable example below uses generated SVG panels to demonstrate B-roll timing without depending on any external media URL. In a production template, replace the SVG stand-ins with IMAGE, VIDEO, or GIF elements from your asset system while keeping the same timing and track ideas.
{
"name": "automate-broll-json-demo",
"resolution": "hd",
"duration": 9,
"frameRate": 30,
"outputFormat": "mp4",
"backgroundColor": "#0B1020",
"visuals": [
{
"type": "SVG",
"width": 1280,
"height": 720,
"track": 1,
"svg": "<svg width='1280' height='720' viewBox='0 0 1280 720' xmlns='http://www.w3.org/2000/svg'><defs><linearGradient id='bg' x1='0' y1='0' x2='1' y2='1'><stop offset='0' stop-color='#0B1020'/><stop offset='1' stop-color='#17233D'/></linearGradient><linearGradient id='accent' x1='0' y1='0' x2='1' y2='0'><stop offset='0' stop-color='#2DD4BF'/><stop offset='1' stop-color='#FADD46'/></linearGradient></defs><rect width='1280' height='720' fill='url(#bg)'/><rect x='64' y='46' width='1152' height='628' rx='30' fill='rgba(255,255,255,0.045)' stroke='rgba(255,255,255,0.13)'/><rect x='104' y='184' width='420' height='286' rx='28' fill='rgba(7,13,30,0.82)' stroke='rgba(255,255,255,0.12)'/><text x='136' y='234' fill='#FFFFFF' font-family='Arial' font-size='28' font-weight='800'>Primary story</text><rect x='136' y='270' width='318' height='18' rx='9' fill='rgba(255,255,255,0.18)'/><rect x='136' y='306' width='248' height='18' rx='9' fill='rgba(255,255,255,0.13)'/><rect x='136' y='342' width='286' height='18' rx='9' fill='rgba(255,255,255,0.13)'/><rect x='136' y='394' width='270' height='54' rx='18' fill='rgba(45,212,191,0.13)' stroke='rgba(45,212,191,0.38)'/><text x='271' y='428' text-anchor='middle' fill='#A7FFF6' font-family='Arial' font-size='18' font-weight='700'>script + narration</text><rect x='104' y='530' width='1072' height='74' rx='18' fill='rgba(0,0,0,0.28)' stroke='rgba(255,255,255,0.1)'/><line x1='152' y1='568' x2='1128' y2='568' stroke='rgba(255,255,255,0.23)' stroke-width='8' stroke-linecap='round'/><rect x='320' y='556' width='200' height='24' rx='12' fill='#2DD4BF'/><rect x='572' y='556' width='220' height='24' rx='12' fill='#FADD46'/><rect x='842' y='556' width='190' height='24' rx='12' fill='#A855F7'/><text x='640' y='644' text-anchor='middle' fill='#C8D2F1' font-family='Arial' font-size='18'>B-roll cues become timed visual layers</text></svg>"
},
{
"type": "TEXT",
"x": 640,
"y": 112,
"width": 1080,
"anchor": "center-center",
"track": 8,
"enterBegin": 0.2,
"enterEnd": 0.8,
"enterAnimation": "fade",
"exitBegin": 8.2,
"exitEnd": 8.8,
"exitAnimation": "fade",
"html": "<div style='text-align:center; color:#ffffff; font-size:36px; font-weight:800; line-height:1.22;'>Automated B-roll from JSON timing</div>"
},
{
"type": "SVG",
"x": 662,
"y": 214,
"width": 430,
"height": 235,
"track": 4,
"enterBegin": 1.1,
"enterEnd": 1.6,
"enterAnimation": "fade",
"exitBegin": 3.1,
"exitEnd": 3.5,
"exitAnimation": "fade",
"svg": "<svg width='430' height='235' viewBox='0 0 430 235' xmlns='http://www.w3.org/2000/svg'><rect width='430' height='235' rx='24' fill='#102A43'/><rect x='24' y='24' width='382' height='128' rx='20' fill='rgba(45,212,191,0.18)' stroke='rgba(45,212,191,0.55)'/><circle cx='94' cy='88' r='34' fill='#2DD4BF' opacity='0.9'/><rect x='154' y='62' width='170' height='18' rx='9' fill='rgba(255,255,255,0.76)'/><rect x='154' y='96' width='118' height='14' rx='7' fill='rgba(255,255,255,0.42)'/><text x='215' y='195' text-anchor='middle' fill='#FFFFFF' font-family='Arial' font-size='26' font-weight='800'>Product close-up</text></svg>"
},
{
"type": "SVG",
"x": 718,
"y": 214,
"width": 430,
"height": 235,
"track": 5,
"enterBegin": 3.4,
"enterEnd": 3.9,
"enterAnimation": "fade",
"exitBegin": 5.7,
"exitEnd": 6.1,
"exitAnimation": "fade",
"svg": "<svg width='430' height='235' viewBox='0 0 430 235' xmlns='http://www.w3.org/2000/svg'><rect width='430' height='235' rx='24' fill='#2B1745'/><rect x='34' y='30' width='362' height='118' rx='20' fill='rgba(168,85,247,0.18)' stroke='rgba(168,85,247,0.58)'/><path d='M72 122 L148 66 L214 118 L270 82 L360 132' fill='none' stroke='#FADD46' stroke-width='10' stroke-linecap='round' stroke-linejoin='round'/><text x='215' y='195' text-anchor='middle' fill='#FFFFFF' font-family='Arial' font-size='26' font-weight='800'>Feature proof</text></svg>"
},
{
"type": "SVG",
"x": 662,
"y": 214,
"width": 430,
"height": 235,
"track": 6,
"enterBegin": 6.0,
"enterEnd": 6.5,
"enterAnimation": "fade",
"exitBegin": 8.1,
"exitEnd": 8.6,
"exitAnimation": "fade",
"svg": "<svg width='430' height='235' viewBox='0 0 430 235' xmlns='http://www.w3.org/2000/svg'><rect width='430' height='235' rx='24' fill='#142B21'/><rect x='38' y='30' width='354' height='118' rx='20' fill='rgba(250,221,70,0.15)' stroke='rgba(250,221,70,0.6)'/><rect x='78' y='60' width='76' height='54' rx='12' fill='#FADD46' opacity='0.92'/><rect x='178' y='60' width='76' height='54' rx='12' fill='#2DD4BF' opacity='0.92'/><rect x='278' y='60' width='76' height='54' rx='12' fill='#FFFFFF' opacity='0.72'/><text x='215' y='195' text-anchor='middle' fill='#FFFFFF' font-family='Arial' font-size='26' font-weight='800'>Outcome shot</text></svg>"
}
]
}
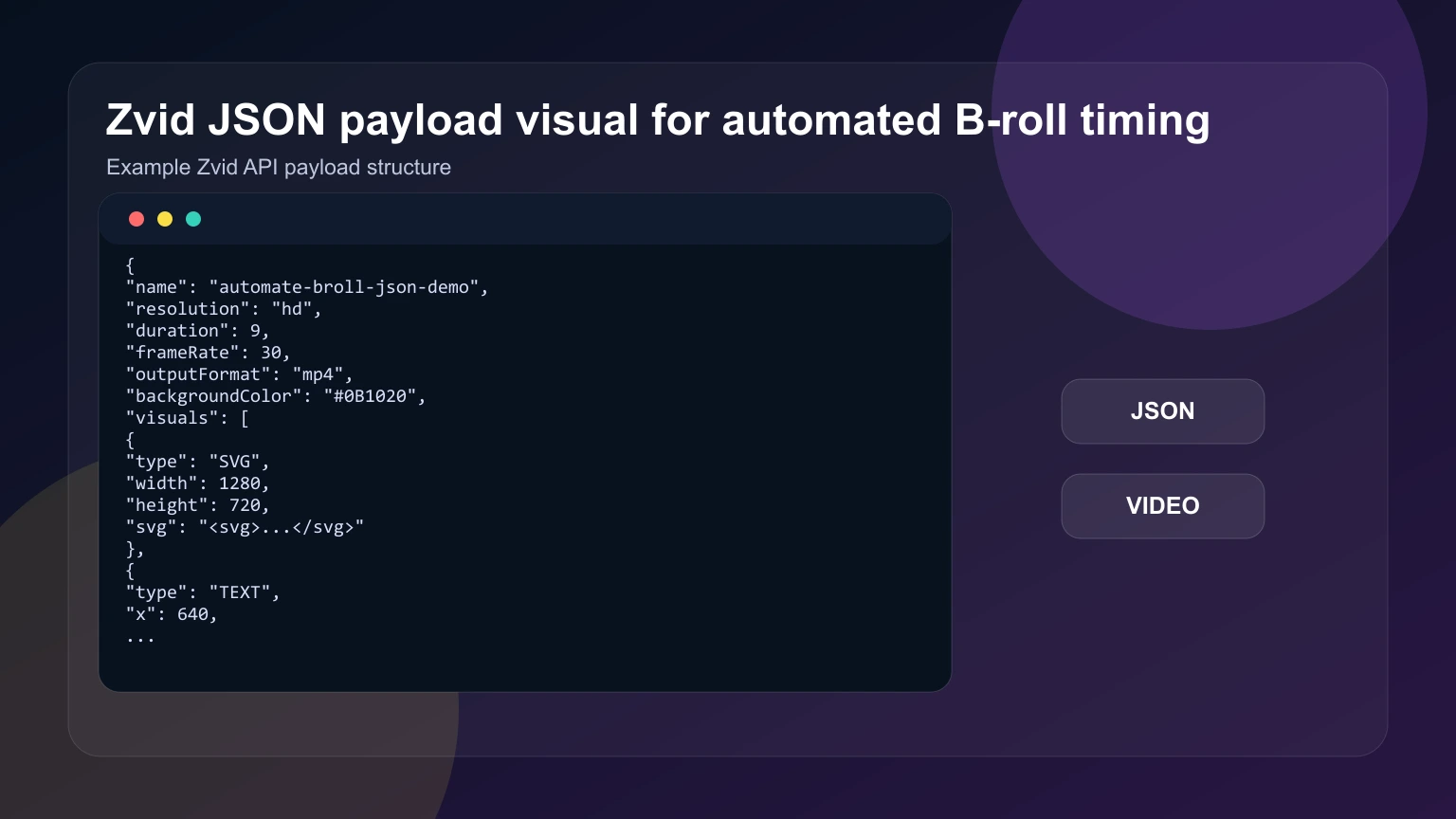
The payload visual is generated from the real renderable B-roll timing example.
For the public API request, wrap the project inside a top-level payload field:
{
"payload": {
"name": "automate-broll-json-demo",
"resolution": "hd",
"duration": 9,
"frameRate": 30,
"outputFormat": "mp4",
"visuals": []
}
}
How the B-roll workflow works
The most reliable B-roll automation systems separate editorial decisions from rendering. The renderer should receive clean timing data. It should not have to infer what the video is about.
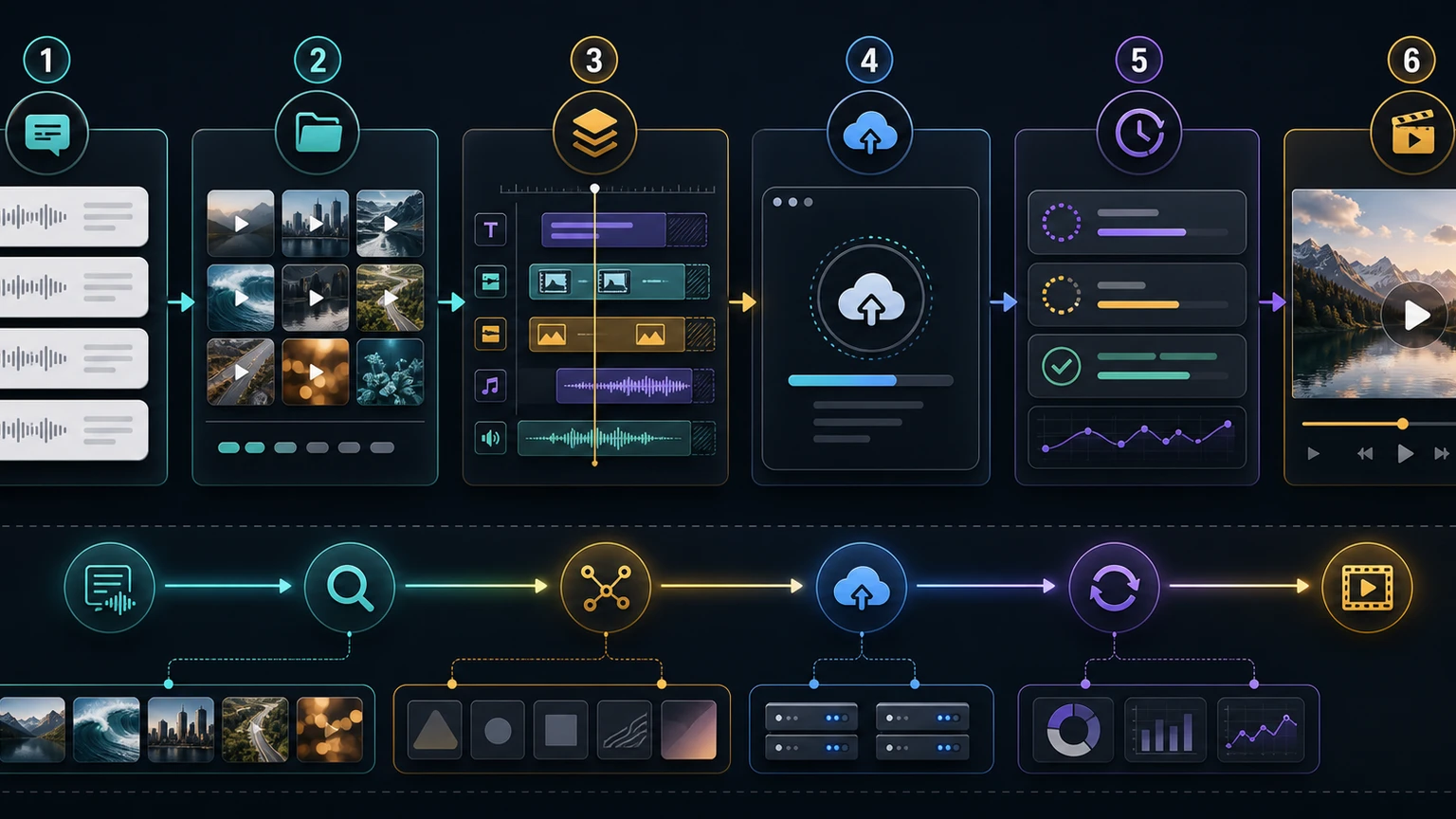
Keep cue extraction, asset selection, JSON assembly, render submission, and job polling as separate steps.
A practical implementation usually looks like this:
- Start with a script, transcript, product feed, tutorial outline, or campaign brief.
- Extract cue windows such as product mention, feature proof, location, testimonial, screenshot, or outcome.
- Match each cue to an approved media asset.
- Convert each matched asset into an
IMAGE,VIDEO, orGIFvisual element. - Add timing, track order, resize behavior, and optional transitions.
- Submit the payload to Zvid and poll the render job until the final video is ready.
This structure makes B-roll easier to review. Editors can approve cue timing and media choices before rendering. Developers can test one generated payload without opening a timeline editor. Marketers can reuse the same placement rules across many product videos, explainers, ads, or social clips.
Mapping B-roll plans from scripts or data
The input to your B-roll system can be human-written or machine-generated. The important part is to normalize it into a simple B-roll plan before you build the Zvid payload.
A readable CSV-style plan might look like this:
label,asset_url,asset_type,start_seconds,end_seconds,editor_note
product close-up,https://example.com/media/product-closeup.jpg,IMAGE,2.2,5.8,Show when the narration names the product
feature proof,https://example.com/media/dashboard-demo.mp4,VIDEO,6.0,11.0,Show dashboard evidence after the feature claim
This CSV is not the Zvid render payload. It is a review-friendly planning layer that editors, AI tools, or automation rules can produce before your application creates renderable JSON. When the plan is approved, your code maps each row into a Zvid visual element: asset_url becomes src, asset_type becomes type, start_seconds becomes enterBegin, and end_seconds becomes exitEnd. The template then adds layout fields such as width, height, position, resize, track, and optional animations.
For feed-driven content, the B-roll plan can be generated from the same data source that fills titles, prices, locations, or product attributes. That is why the CSV-to-video pattern maps well to B-roll: the data decides which supporting media appears, while the template controls where and how it appears.
Where AI video and B-roll footage fit
AI can help with B-roll automation, but it should feed the pipeline rather than replace the template. A prompt can ask an AI model to read a script, transcript, subtitle file, or product description and suggest cue windows such as "show dashboard," "show product close-up," "show customer outcome," or "show location context." Your app can then match those suggestions to approved stock footage, product media, image generation outputs, or an internal asset library.
That distinction matters for short-form videos, YouTube Shorts, Instagram Reels, tutorials, and product explainers. Content creators may want the speed of an AI B-roll generator, while teams still need predictable layout, caption safety, brand rules, and final video review. JSON is the handoff between the creative cue and the rendering API.
A useful AI-assisted pipeline looks like this:
- Use AI or editorial rules to identify relevant B-roll footage windows.
- Search an approved source such as an internal media library, Pexels-style stock footage, product screenshots, or generated images.
- Convert the selected asset into a timed Zvid visual layer.
- Render the final video through the API with a server-side API key.
- Store the prompt, cue list, payload, and render job ID for review.
This keeps video production repeatable. If a generated cue is weak, you can improve the prompt or asset matcher. If the layout is weak, you can improve the JSON template. If the final video needs a different format, you can adjust the composition without changing the cue extraction step.
This is also where orchestration tools can sit around the render API. A team might use OpenAI for transcript analysis, a Pexels-style media search for stock footage, n8n or another workflow tool to move data between systems, and GitHub to version prompt and template changes. Zvid's role is the video creation step that turns the approved cue list into the final video through an API.
Prompt-only B-roll has limits. It may find a relevant topic but still choose the wrong shot, miss the original video pacing, place B-rolls over a caption, or produce a clip that feels generic instead of professional video. A video editor can catch those issues manually, but automation needs the same judgment encoded as reviewable data. Keep the cue list, prompt, selected asset URL, and JSON layer visible so reviewers can fix finding the right B-roll footage without rebuilding the whole video with AI.
Timing, tracks, resize, and transitions
B-roll quality depends less on how many clips you add and more on whether the timing and layout respect the viewer's attention.
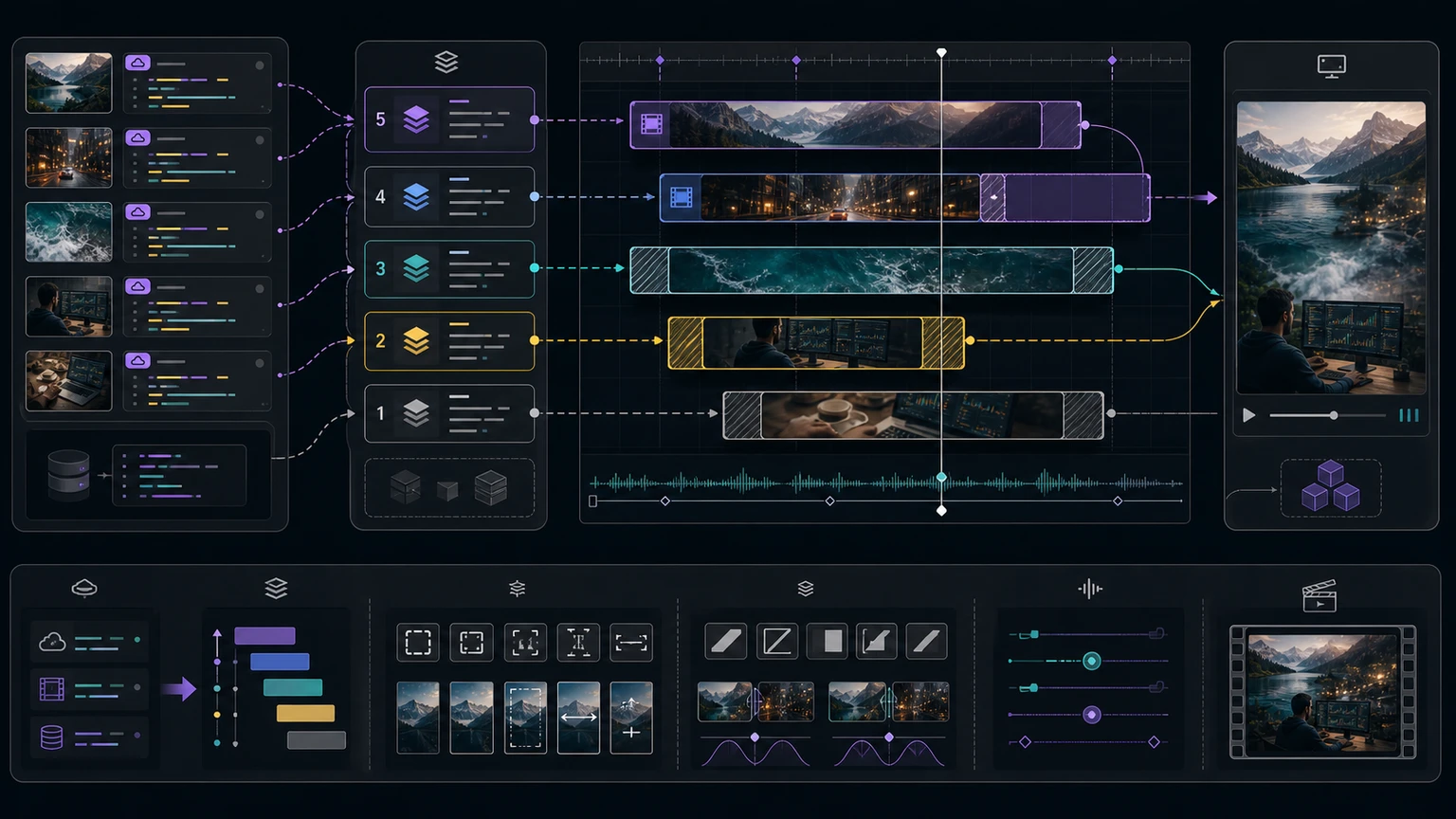
B-roll layers need timing, layout, and track order, not just asset URLs.
Use these rules as a starting point:
- Set
enterBeginandexitEndfrom the cue window. - Use
enterEndandexitBeginwhen you want a fade or other entrance and exit effect. - Use
trackso titles, captions, and callouts sit above B-roll when needed. - Use
resize: "cover"for full-frame B-roll andresize: "contain"when the full asset must remain visible. - Use
position,x,y,width, andheightto create picture-in-picture or side-by-side layouts. - Use video transitions only between coordinated
VIDEOelements when the handoff is intentional.
Do not turn every cue into a cutaway. B-roll is strongest when it clarifies the spoken point, shows proof, or adds visual context. Too much movement can make a generated video feel noisy even when every JSON field is valid.
For a talking-head explainer, B-roll often works well as short full-frame cutaways or picture-in-picture inserts. For product videos, it may be a sequence of product photos, feature screenshots, and outcome shots. For tutorials, it can be screen recordings or annotated UI steps. In each case, the JSON model stays the same: timed visual layers on a shared composition timeline.
API workflow for rendering B-roll
After your payload is ready, submit it through the Zvid render endpoint:
curl -X POST https://api.zvid.io/api/render/api-key \
-H "Content-Type: application/json" \
-H "x-api-key: YOUR_API_KEY" \
-d @broll-render.json
Save the returned job ID, then poll the job endpoint:
curl -X GET https://api.zvid.io/api/jobs/$JOB_ID \
-H "x-api-key: YOUR_API_KEY"
Your application should treat rendering as asynchronous. Store the source cue list, the generated payload, the render job ID, and the final result URL together. That makes it much easier to debug a wrong asset, a mistimed cue, or a layout issue after the video has been generated.
If a render fails, inspect the payload your app sent rather than only checking the source data. The bug may be in the cue extractor, asset matcher, JSON mapper, or template. Keeping those stages separate makes automated B-roll easier to operate at scale.
Common mistakes
The biggest mistake is treating B-roll as a list of media URLs instead of a timeline. A URL alone does not define pacing, layout, layering, or audio behavior.
Other mistakes show up often:
- Adding B-roll before the narration introduces the concept.
- Letting cutaways hide important captions, titles, or product details.
- Forgetting
volume: 0on supporting video clips when narration should stay dominant. - Using
containwhen the B-roll should fill the frame, orcoverwhen the full screenshot must remain visible. - Putting every visual on the same
trackand getting unexpected layer order. - Creating transition chains before the basic timing is clear.
- Using assets with inconsistent aspect ratios without testing the layout.
- Generating cues from AI output without editorial review.
- Forgetting that render jobs are asynchronous.
- Reusing one B-roll template across portrait, square, and landscape formats without layout changes.
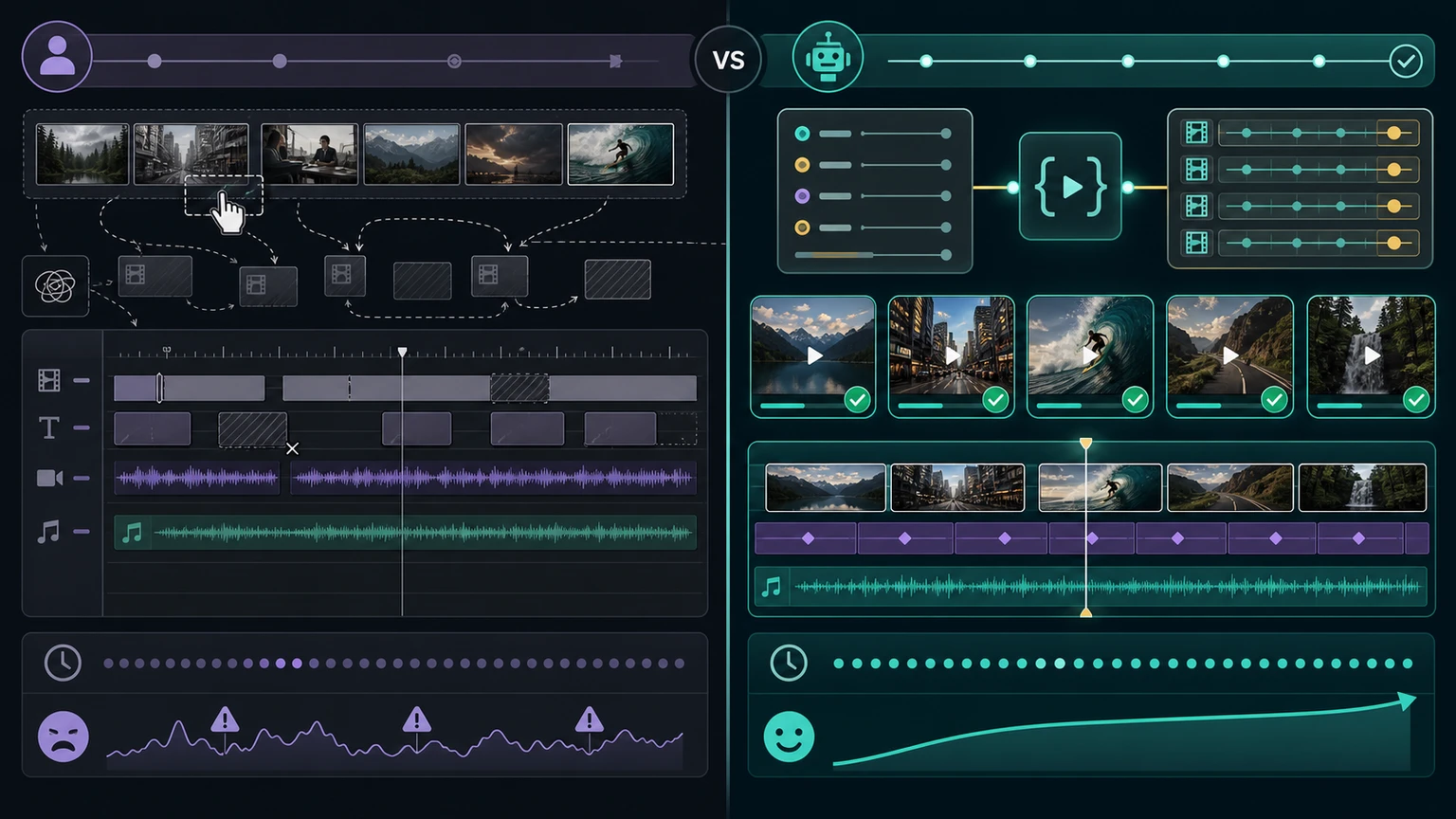
JSON-driven B-roll is strongest when placement rules are repeatable and reviewable.
The fix is to make B-roll part of the template contract. Define the allowed asset types, expected cue duration, track order, audio behavior, and layout variants before you generate hundreds of payloads.
When to use Zvid
Use Zvid when your application needs to generate videos from structured data and repeat the same B-roll logic across many outputs. It is a strong fit for agencies, AI video tools, ecommerce teams, tutorial platforms, internal enablement systems, and marketing operations teams that already know what supporting media should appear.
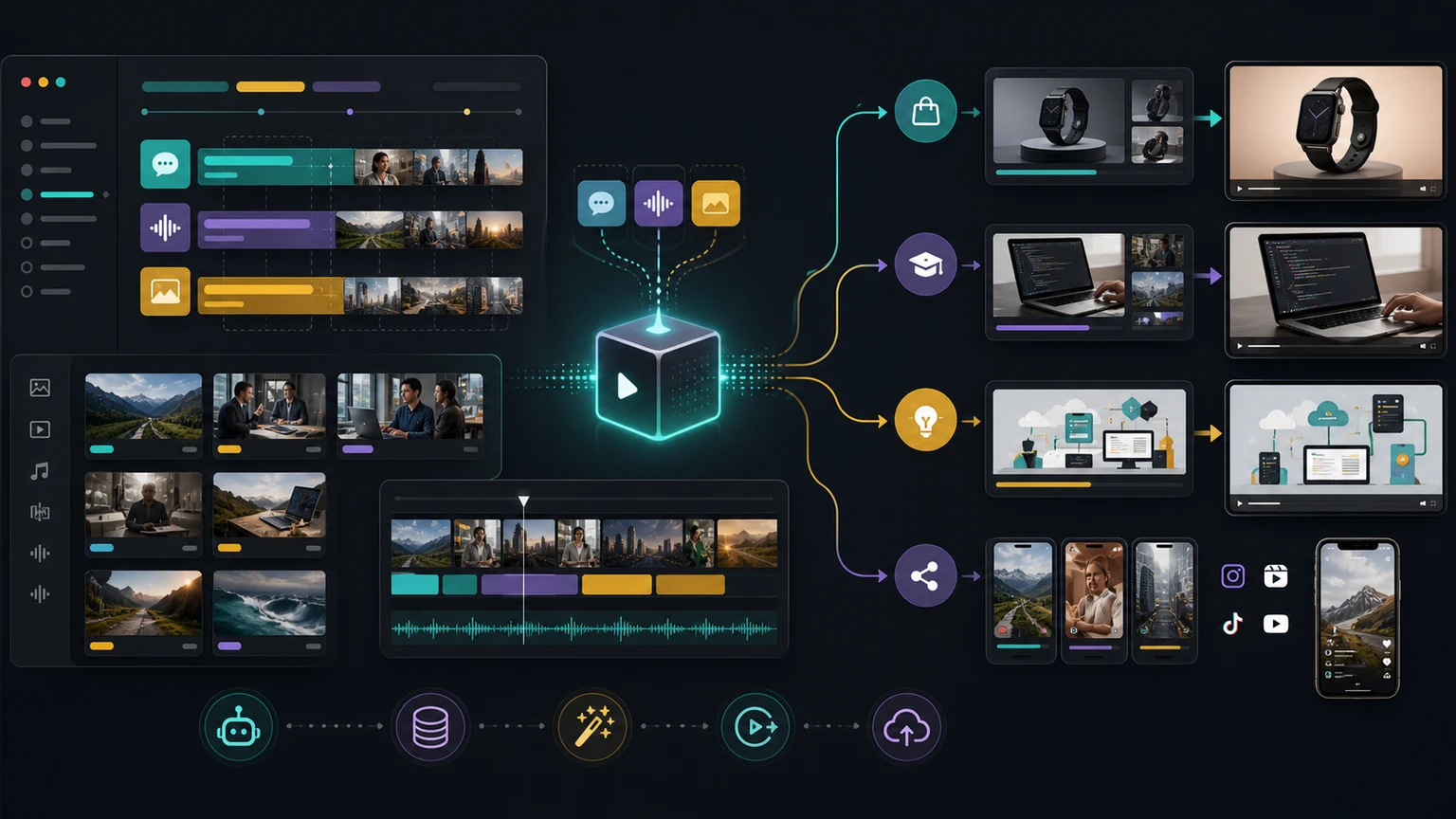
One cue system can power many video formats when B-roll is modeled as data.
Zvid is especially useful when you need:
- Timed media layers generated from scripts, transcripts, feeds, or campaign rules.
- Repeatable B-roll placement across many videos.
- A JSON payload that controls scene layout, media, text, timing, and output settings.
- A hosted API workflow for render submission and job polling.
- Clear handoff between editorial cue review and automated rendering.
If your team only needs one carefully edited hero video, a manual editor may be the right tool. If you need product cutaways, tutorial inserts, social proof clips, or campaign variations generated repeatedly, JSON B-roll gives your app a better system boundary.
Start with one short cue list, map it into a Zvid payload, render the result, and inspect the timing before you scale the same template across more videos.
FAQs
What is automated B-roll?
Automated B-roll is supporting video, image, GIF, or graphic content placed on a timeline by software instead of manually edited clip by clip.
Can I add B-roll with JSON?
Yes. In Zvid, add B-roll as timed visual elements in the visuals array. Use IMAGE, VIDEO, GIF, SVG, or TEXT depending on the asset and layout.
Which fields control B-roll timing?
Use enterBegin, enterEnd, exitBegin, and exitEnd to control when each element appears and disappears on the timeline.
How do I keep B-roll from covering titles or captions?
Use track deliberately. Lower tracks render behind higher tracks, so keep background B-roll lower than titles, captions, and callouts.
Should B-roll video clips include audio?
Only when the source audio is part of the final story. For most narration-led workflows, set supporting video clips to volume: 0.
Can I use images instead of video clips for B-roll?
Yes. Product photos, screenshots, still frames, and generated graphics can work well as B-roll when they are timed and positioned correctly.
How do I choose between cover and contain?
Use cover when the asset should fill its frame and cropping is acceptable. Use contain when the entire asset must remain visible, such as UI screenshots or charts.
Can AI help choose B-roll cues?
Yes, AI can suggest cue windows from a script or transcript, but teams should still review cue quality, asset relevance, and timing before rendering.
Is B-roll automation useful for product videos?
Yes. Product feeds can map images, feature screenshots, benefit cards, and outcome shots into repeatable B-roll scenes.